
自动化流程与AI深度赋能,高效处理海量数据,全面挖掘并释放数据价值。

采用模块化弹性设计,无缝适配多场景动态需求,确保系统稳定高效运行。

构建全周期加密管控体系,融合隐私计算技术,全方位筑牢数据安全防线。

依托开放接口对接多元生态,打破数据孤岛,驱动产业协同与创新升级。
自动化流程与AI深度赋能,高效处理海量数据,全面挖掘并释放数据价值。
采用模块化弹性设计,无缝适配多场景动态需求,确保系统稳定高效运行。
构建全周期加密管控体系,融合隐私计算技术,全方位筑牢数据安全防线。
依托开放接口对接多元生态,打破数据孤岛,驱动产业协同与创新升级。

对各类数据源的采集,包括结构化数据、半结构化数据和非结构化数据,如数据库、日志、API等

通过消除“垃圾进、垃圾出”风险,数据清洗能力为业务系统提供“即用型”数据资产。

数据引擎的“治理中枢”,聚焦数据的全生命周期管理,确保数据的合规性、安全性和可管理性。

将清洗治理后的数据转化为业务洞察,支持从基础查询到高级智能分析的全场景需求。
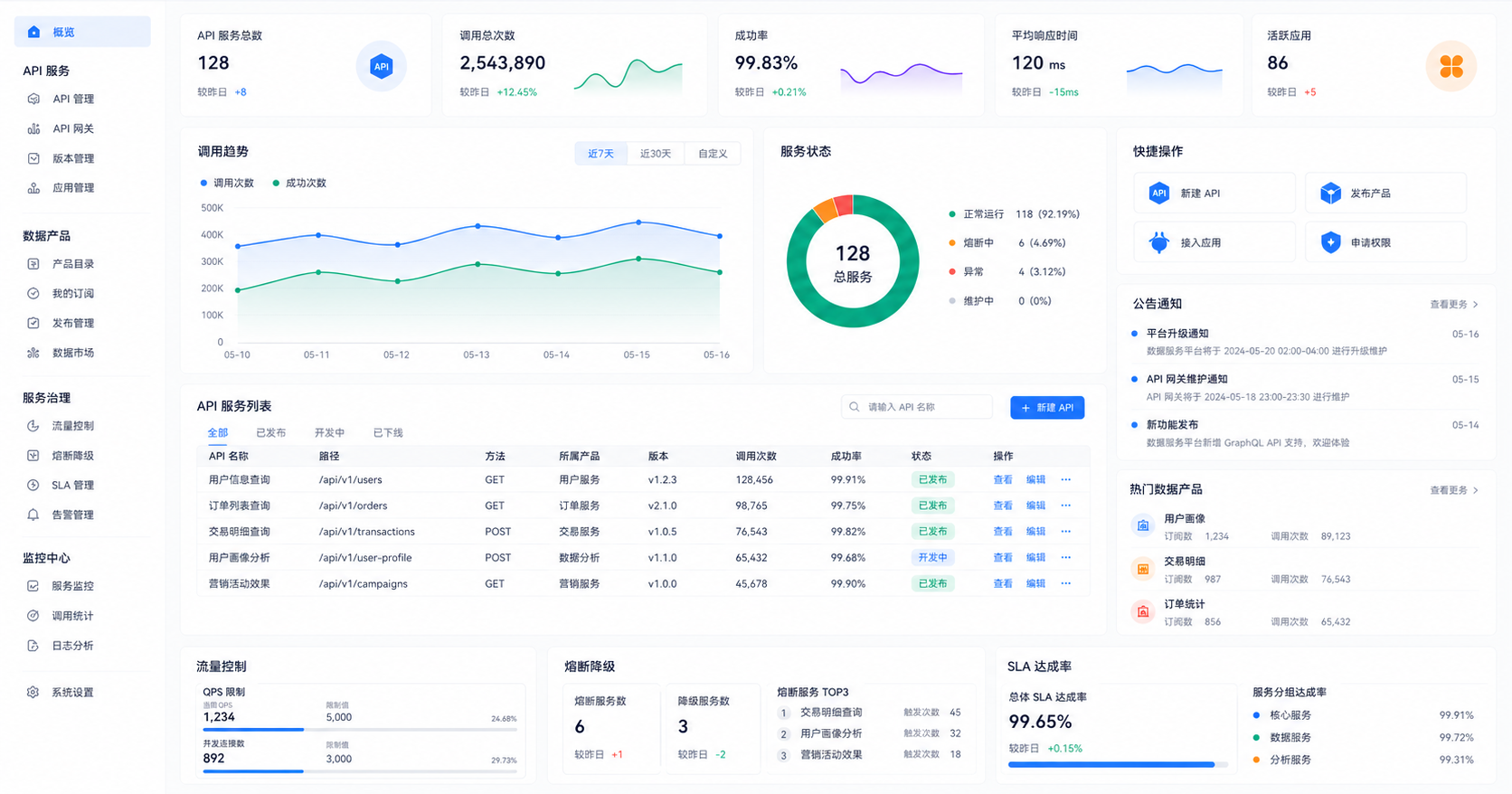
将数据以服务化、API化的方式高效分发给上层业务系统。
对各类数据源的采集,包括结构化数据、半结构化数据和非结构化数据,如数据库、日志、API等
通过消除“垃圾进、垃圾出”风险,数据清洗能力为业务系统提供“即用型”数据资产。
数据引擎的“治理中枢”,聚焦数据的全生命周期管理,确保数据的合规性、安全性和可管理性。
将清洗治理后的数据转化为业务洞察,支持从基础查询到高级智能分析的全场景需求。
将数据以服务化、API化的方式高效分发给上层业务系统。

引擎整合实时与历史数据,实现毫秒级洞察,取代滞后报表。全链路自动化缩短响应周期,实现数据驱动的敏捷决策。

通过开放API打破数据孤岛,业务部门可快速调用高质量数据,孵化智能风控、精准营销等场景,加速产品迭代。

模块化弹性架构降低硬件依赖,自动化工作流替代人工操作,减少错误。资源智能调度避免算力浪费,实现降本增效。

全生命周期安全体系覆盖数据采集、存储到服务,结合加密传输与权限隔离,确保数据可追溯,规避合规风险。
引擎整合实时与历史数据,实现毫秒级洞察,取代滞后报表。全链路自动化缩短响应周期,实现数据驱动的敏捷决策。
通过开放API打破数据孤岛,业务部门可快速调用高质量数据,孵化智能风控、精准营销等场景,加速产品迭代。
模块化弹性架构降低硬件依赖,自动化工作流替代人工操作,减少错误。资源智能调度避免算力浪费,实现降本增效。
全生命周期安全体系覆盖数据采集、存储到服务,结合加密传输与权限隔离,确保数据可追溯,规避合规风险。
科技赋能行业,全面拥抱数字化




科技赋能行业,全面拥抱数字化

